Distilling CLIP with Dual Guidance for Learning Discriminative Human Body Shape Representation
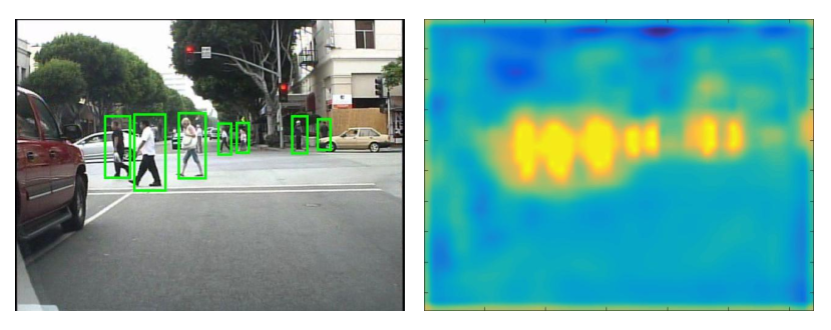
Feng Liu, Minchul Kim, Zhiyuan Ren, Xiaoming LiuPerson Re-Identification (ReID) holds critical importance in computer vision with pivotal applications in public safety and crime prevention. Traditional ReID methods, reliant on appearance attributes such as clothing and color, encounter limitations in long-term scenarios and dynamic environments. To address these challenges, we propose CLIP3DReID, an innovative approach that enhances ...
Continue readingKeywords: Person Re-identification, 3D Human Reconstruction